Avec l’émergence du travail hybride, les expériences utilisateur médiocres sont devenues beaucoup trop courantes : les utilisateurs se plaignent quotidiennement de la lenteur des applications, des coupures de réseau et des pannes de matériel. En outre, la grande majorité de ces problèmes sont considérés comme résolus parce qu’ils disparaissent, et non parce que la cause profonde du problème a été identifiée.
L’analyse des causes profondes exige que les données (plus précisément, un volume important de données) soient recueillies d’une manière synchronisée, contextuelle et suffisamment large pour identifier (ou exclure) les coupables potentiels. Ces données ne sont toutefois pas faciles à collecter et à analyser à l’aide des techniques de surveillance classiques. De plus, les problèmes de performance impactent les utilisateurs et les applications qui peuvent se trouver n’importe où, ce qui rend d’autant plus difficile la collecte des bonnes données depuis les bons endroits.
Dans mon ancien poste d’analyste chez Gartner, le principal défi auquel mes clients étaient confrontés n’était pas le manque de données sur les performances, mais l’incapacité d’utiliser de nombreux silos de données de performance non corrélées pour résoudre réellement un problème. Les outils de surveillance cloisonnés qui se concentraient sur un seul domaine étaient utilisés pour rejeter la faute sur une autre équipe ; par exemple les équipes chargées des applications pointaient du doigt les équipes chargées du réseau qui, à leur tour, pointaient du doigt la sécurité ou l’informatique de l’utilisateur final. Encore fallait-il que ces outils existent. Certains environnements client souffraient d’un manque total de visibilité.
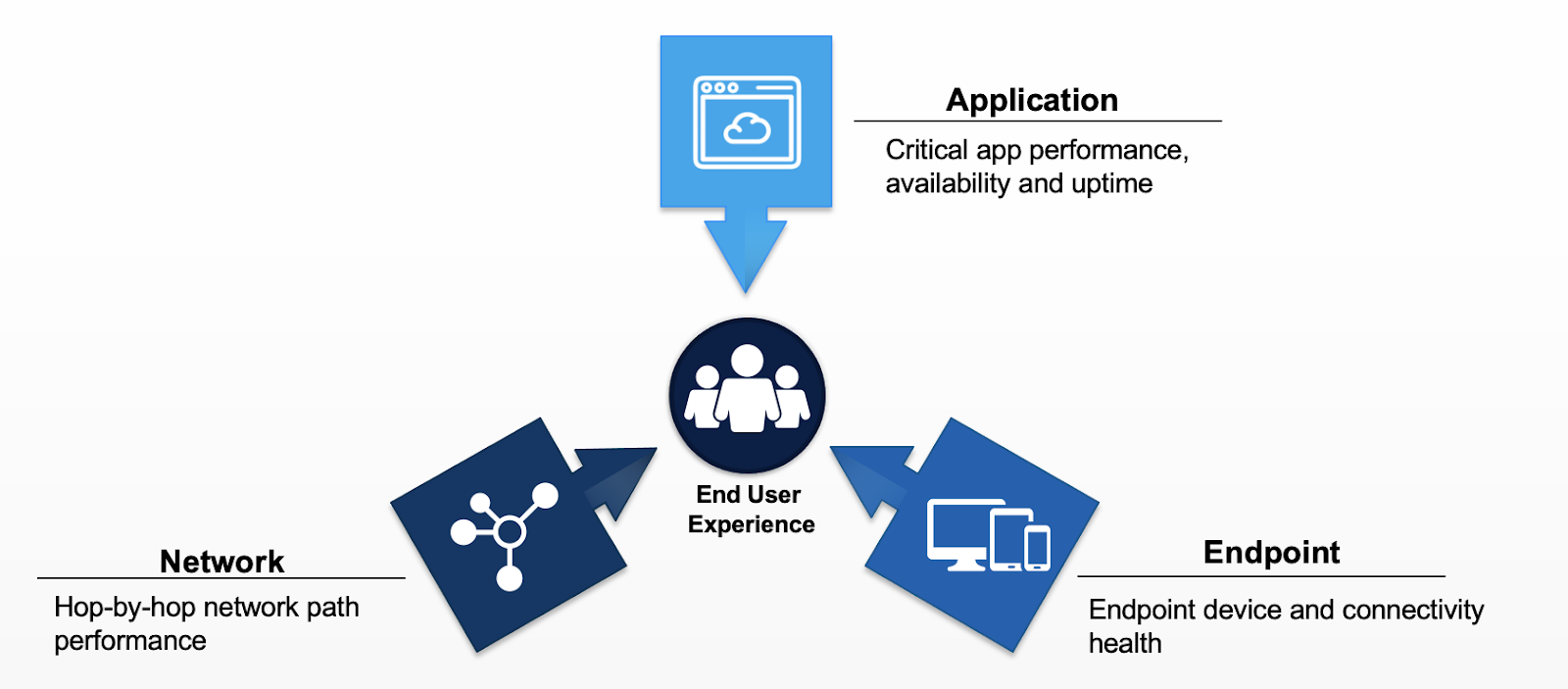
Figure 1 : Le suivi de l’expérience digitale requiert la collecte, la corrélation et la visualisation de diverses données de télémétrie des performances pour obtenir des informations exploitables pour tous les utilisateurs.
Tout diagnostic complet capture à la fois des séries temporelles et des données d’événements dans les trois domaines principaux de cause potentielle : l’application, le réseau et le terminal ( ou l’endpoint). Cette approche fournit suffisamment de preuves pour déterminer avec certitude l’origine du problème et le résoudre.
Comme nous le savons, les données peuvent être confuses et il est rare de trouver des preuves irréfutables d’un problème. Par exemple, un appel Microsoft Teams brouillé ou une application lente peuvent résulter d’un certain nombre de causes sous-jacentes. Les solutions DEM ont été conçues pour résoudre ce problème, mais elles doivent capturer une véritable expérience utilisateur et analyser toutes les causes sous-jacentes potentielles, telles que le terminal, le réseau, l’application et la sécurité, pour identifier la cause profonde.
Comme le montre la Figure 2, il est essentiel de commencer par une mesure objective de l’expérience de l’utilisateur final (chargement lent des pages, mauvaise qualité des appels). Il s’agit ensuite d’établir une corrélation entre la mauvaise expérience utilisateur et les différentes causes sous-jacentes potentielles.
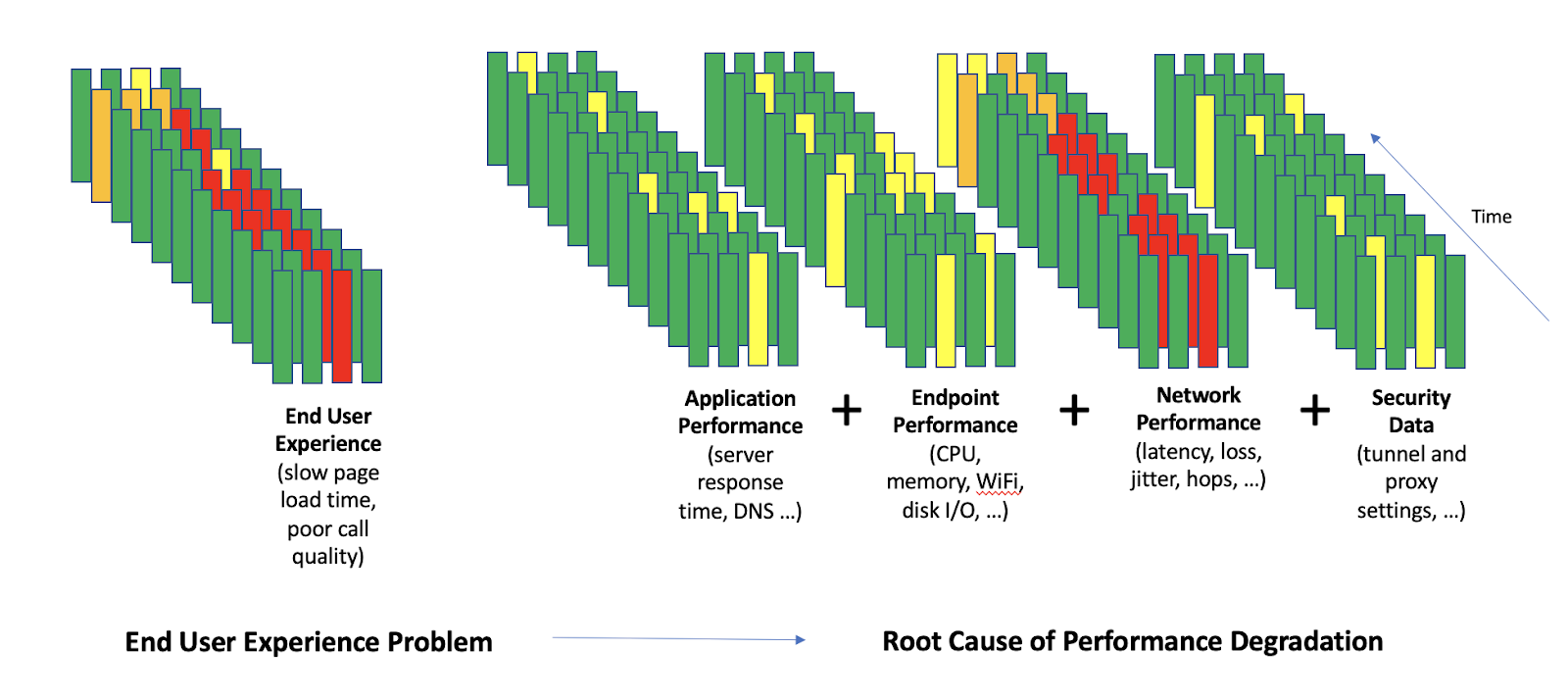
Figure 2 : L’analyse des causes profondes nécessite un large éventail de points de données pour réussir à séparer le signal du bruit.
À titre d’exemple, il y a quelques semaines, un employé de Zscaler a soudainement constaté de graves dégradations de performances impactant toutes les applications, mais plus spécialement Zoom. Zoom étant une application en temps réel, les fluctuations de la connectivité sont particulièrement perceptibles. Après examen dans ZDX, un problème lié à Zoom a été confirmé car son score ZDX avait chuté, indiquant un certain nombre de baisses au cours de la journée.

Figure 3 : Zoom présentent des baisses de performance.
La première étape a consisté à vérifier le serveur et les temps de résolution DNS afin de déterminer si ces baisses pouvaient être corrélées. Ce n’était pas le cas.


Figure 4 : Les temps de réponse du serveur et les temps de réponse du DNS sont stables.
L’étape suivante a consisté à analyser la latence du réseau de bout en bout et, bien qu’elle ait été légèrement irrégulière, la latence totale était inférieure à 25 ms et n’était vraisemblablement pas la cause principale du problème.

Figure 5 : La latence est relativement stable et constamment inférieure à 25 ms.
Enfin, l’appareil de l’utilisateur final lui-même a été examiné. Les mesures de santé de l’appareil semblaient correctes, avec une utilisation du processeur, de la mémoire et du disque dans des limites acceptables.
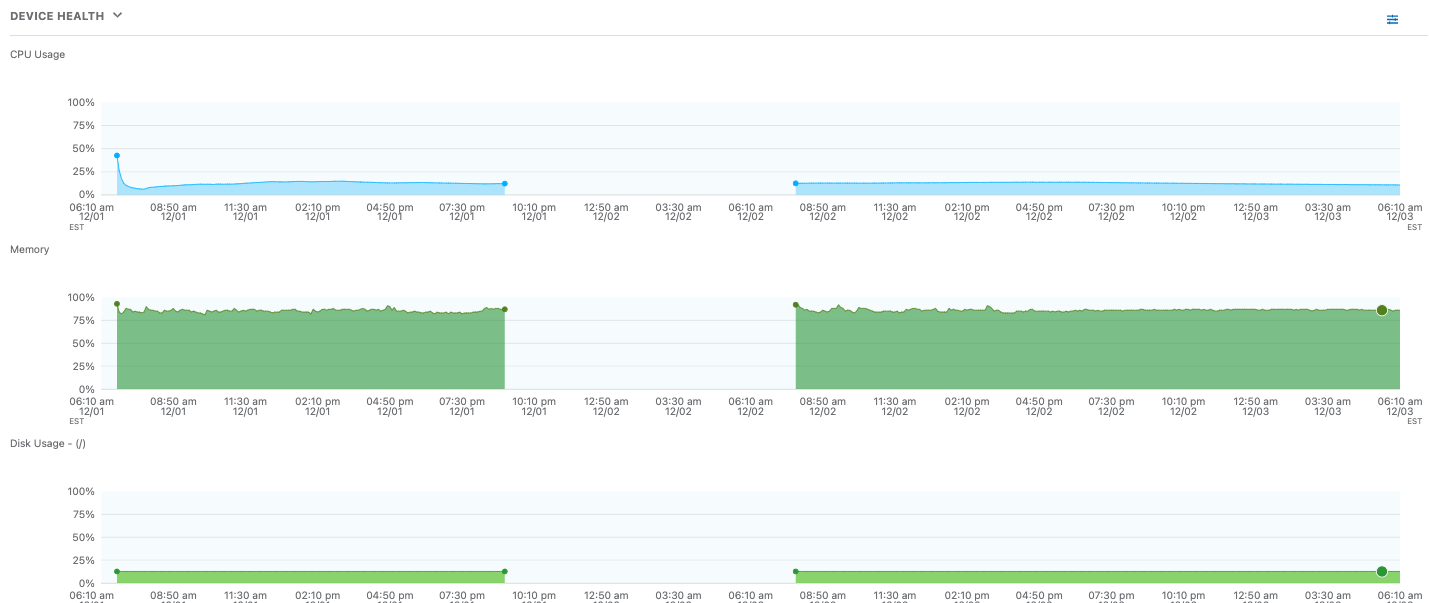
Figure 6 : La santé de l’appareil, en termes d’utilisation du processeur, de la mémoire et du disque, est correcte.
Alors que les mesures de l’appareil semblaient correctes, les événements de l’appareil de l’utilisateur ont mis en évidence des changements dans les attributs de l’appareil. Il en est ressorti que l’attribut Gateway_MAC_Address oscillait entre une valeur valide et une valeur null, une valeur null signifiant que l’appareil perdait temporairement la connexion avec son prochain saut. Étant donné que cette chaîne d’événements indiquait un problème de deuxième couche entre l’appareil et la passerelle, l’utilisateur a redémarré sa passerelle (ce qui n’a pas été utile) et a finalement remplacé son appareil de passerelle, ce qui a permis de résoudre le problème.

Figure 7 : Les événements de l’appareil mettent en évidence des changements dans les attributs de l’appareil, indiquant un problème de deuxième couche entre l’appareil et la passerelle.
Lorsqu’il s’agit de trouver la cause profonde des problèmes de performance, il est essentiel de disposer de toutes les données appropriées à tous les bons endroits.
Pour plus d’informations sur la façon dont Zscaler et ZDX fournissent ce niveau de visibilité pour permettre l’analyse des causes profondes, rendez-vous ici.
(La figure 2 s’inspire de l’excellent travail de Greg Murray, analyste chez Gartner, que vous trouverez ici. Un abonnement à Gartner est nécessaire).





