Pourquoi des SLA ?
Les accords de niveau de service (SLA) — dans le contexte de ce blog — sont l’expression de la confiance qu’un fournisseur de sécurité du cloud manifeste dans sa capacité à fournir un service résilient, évolutif et performant. Les SLA se sont généralisés au fur et à mesure que les solutions SaaS gagnaient en popularité, offrant aux entreprises des garanties quant à leurs niveaux de service, tels que les performances et la disponibilité, sur un grand parc de ressources partagées. Bien que les SLA fassent généralement l’objet d’une attention particulière de la part des avocats, toutes les parties prenantes à une décision d’achat devraient comprendre les SLA d’un fournisseur pour :
- Identifier les impacts commerciaux de la fiabilité, de la vitesse et de l’expérience globale de l’utilisateur associés au service
- Quantifier le risque en comprenant les exclusions prévues par l’accord
- Différencier les leaders et innovateurs du secteur des autres fournisseurs qui utilisent des formulations astucieuses pour créer l’illusion d’un SLA de qualité
Dans cet article, nous examinerons en détail les SLA des fournisseurs de services de sécurité cloud, pour Zscaler et d’autres, afin de :
- Découvrir le secret de Zscaler pour fournir les meilleurs SLA du secteur
- Dévoiler et analyser les composants les plus importants des SLA, avec un examen approfondi du SLA sur la latence du proxy
- Vous procurer des critères d’évaluation pour différencier les meilleurs SLA du secteur de ceux d’autres fournisseurs, trop souvent truffés d’exclusions qui nuisent à la finalité du SLA
L’approche de Zscaler en matière de SLA : identifier l’ingrédient secret
Tout simplement, l’ingrédient secret de SLA leaders du marché consiste en un cloud sécurisé leader du marché. Vous ne pouvez pas passer directement aux SLA sans pouvoir les prendre en charge.
Chez Zscaler, la garantie de nos SLA leaders du secteur est le résultat de plus d’une décennie de travail de développement, de construction et d’exploitation du plus grand cloud de sécurité au monde, conçu pour sécuriser le trafic stratégique. De nombreux fournisseurs ont essayé de reproduire notre approche, masquant leur manque de différenciation technique dans des SLA qui semblent satisfaisants en surface, mais qui sont trompeurs en pratique.
Voici quelques-uns des principaux attributs des autres fournisseurs :
Fournisseurs de produits CASB ponctuels qui tentent de se développer sur de nouveaux marchés :
- Plateforme conçue pour des tâches simples comme l’analyse hors bande des applications SaaS à l’aide d’API REST, par opposition au traitement du trafic stratégique au débit de ligne, qui requiert une approche et un ADN très différents
- Stratégie de produit axée sur l’annonce de « fonctionnalités » à cocher avant les rapports d’analystes de marque (par ex. Gartner MQ) plutôt que sur la découverte et la résolution des problèmes spécifiques des clients
- Architectures basées sur le projet open-source Squid proxy, qui n’a jamais réussi à évoluer
Fournisseurs de matériel obsolète essayant de rester pertinents :
- Réutiliser des appliances virtuelles à entité unique sur IaaS (c.-à-d. GCP, AWS) avec des data centers de calcul limités, un modèle de responsabilité partagée et une disponibilité peu fiable
- Chaîner des services en y greffant des services existants et nouveaux qui introduisent de la complexité et de la latence avec chaque capacité supplémentaire
- Mises à jour irrégulières des services et des OS pour les pare-feu de VM (par ex. 6 à 9 mois pour la mise à jour des OS afin de migrer des pare-feu physiques vers les pare-feu de VM hébergés dans le cloud public)
Ces approches ont démontré leurs considérables limites pour fournir un service de qualité et les SLA qui y sont associés. Nous expliquerons ces limites plus en détail par la suite.
Fiers de démontrer notre envergure
Lorsque vous évaluez les SLA d’un fournisseur, vous évaluez, par essence, la solidité de sa plateforme cloud. Sans données accessibles au public concernant l’échelle et les performances, comment pouvez-vous réellement évaluer la plateforme et les SLA qui y sont associés ? Zscaler est le seul fournisseur du secteur à partager publiquement ses données afin d’étayer ses déclarations d’échelle et de performance.
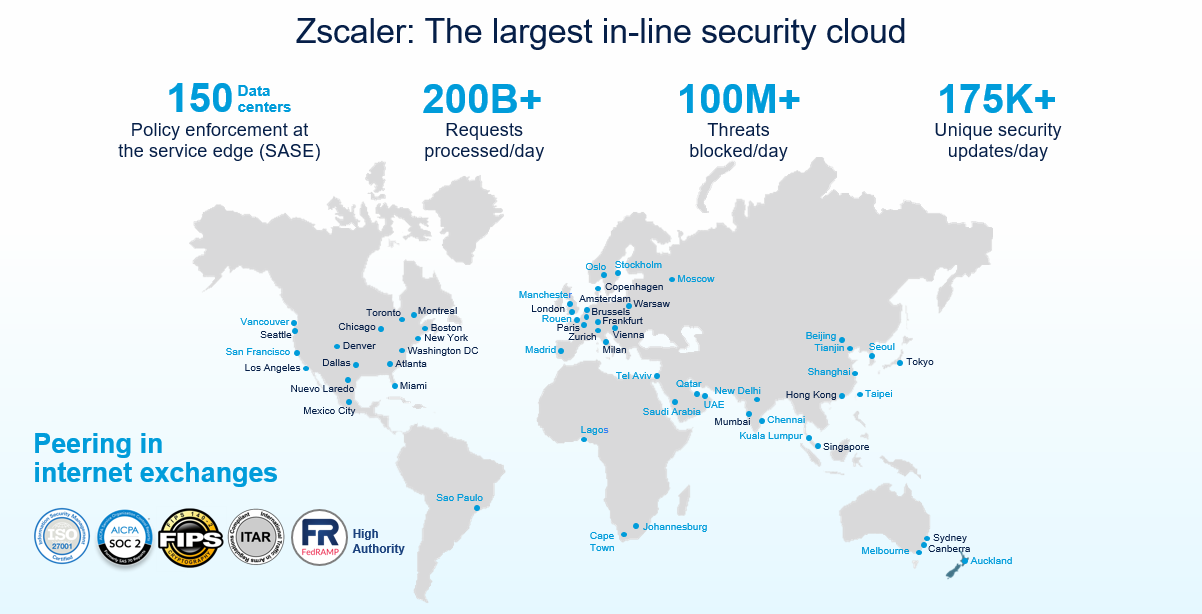
L’empreinte mondiale de Zscaler : 100 % de data centers de calcul (pas de on-ramps ou de vPoP)
Nous sommes tellement confiants dans nos déclarations d’échelle que nous voulons que vous puissiez les constater par vous-même, à tout moment, avec des données en temps réel. Consultez le tableau de bord d’activité de Zscaler Cloud pour vérifier ces mesures à la seconde près.
Matière à réflexion :
Pourquoi aucun autre fournisseur ne communique-t-il des données ou des mesures publiques sur son échelle ou sur le fonctionnement de son cloud ? (astuce de pro : la photo d’une voiture de course pour symboliser la vitesse ne constitue PAS une preuve)
Les SLA de Zscaler : haute disponibilité, sécurité supérieure et vitesse fulgurante
Ceci est l’essence même des SLA de Zscaler Internet Access (ZIA) tels que décrits sur notre fiche produit. L’exploitation du cloud sécurisé leader de l’industrie exige des SLA leaders de l’industrie :
1. Le SLA (favorable au client) de haute disponibilité
En général, c’est ici que les fournisseurs rivalisent sur leur nombre de 9 (vous les verrez couramment utiliser des termes comme « 5-neuf », c’est-à-dire 99,999 %, de disponibilité). Plus le nombre de 9 est élevé, plus l’engagement de disponibilité est fort. Par exemple, avec une disponibilité de 99,9 %, un fournisseur garantit que son service ne sera pas indisponible pendant plus de 525 minutes par an : (1-99,9 %) x 525 600 (525 600 est le nombre de minutes dans une année). Un fournisseur avec cinq 9, soit 99,999 %, s’engagera à moins de 6 minutes de temps d’arrêt par an.
Si vous lisez attentivement nos SLA, vous constaterez que Zscaler propose un accord innovant basé sur le pourcentage de transactions perdues en raison d’un temps d’arrêt ou d’une lenteur plutôt que sur le pourcentage de temps pendant lequel le service n’était pas disponible. Ce SLA favorable au client s’aligne étroitement sur l’impact commercial réel des temps d’arrêt et permet même de récupérer des crédits lorsque le service est disponible à 100 %, mais que le client subit un ralentissement dû à une congestion inattendue.
Matière à réflexion :
Si vos transactions chutaient de 20 % en raison d’une congestion, votre fournisseur affirmerait-il que le service est disponible à 100 % ?
C’est là que les fournisseurs de lift-and-shift (stratégie consistant à faire migrer une application ou une activité d’un environnement à un autre sans procéder à une refonte), qui exécutent leurs anciennes VM à entité unique sur IaaS, rencontrent le plus de difficultés en raison du manque de contrôle et de l’imprévisibilité de l’infrastructure sous-jacente. Il n’est pas rare de voir ces fournisseurs surcharger leurs SLA d’une longue liste d’exclusions, ce qui va à l’encontre de l’objectif du SLA.
Dans cet exemple, un ancien fournisseur de NGFW exclut du SLA les mises à niveau non planifiées, le rendant ainsi sans valeur :

Matière à réflexion :
Si le cloud subit une interruption inattendue et sans préavis, mais que cela ne compte pas comme un temps d’arrêt, alors qu’est-ce qui compte ? N’est-ce pas là la définition même du temps d’arrêt ?
Dans un autre exemple, le même fournisseur de NGFW traditionnel exclut de son SLA les événements de mise à l’échelle :

Matière à réflexion :
L’un des principaux objectifs des services fournis dans le cloud n’est-il pas de supprimer les frais généraux et les soucis liés à la mise à l’échelle ?
2. Le SLA concernant la capture de 100 % des virus connus (sécurité supérieure)
Un proxy hyper-scalaire devrait non seulement offrir une expérience utilisateur ultra rapide, mais aussi une sécurité supérieure sans compromis. Si tout ce dont nous avions besoin était de faire passer des paquets d’un point A à un point B sans analyse, nous aurions pu fournir une latence de 0 ms, mais avec une sécurité épouvantable. Le SLA sur la capture des virus connus est une première dans l’industrie qui, une fois de plus, joint le geste à la parole en matière de sécurité supérieure. Nous nous engageons à empêcher 100 % de tous les logiciels malveillants/virus connus de s’infiltrer sur notre plateforme. Vous obtiendrez une compensation pour chaque raté.
D’autres fournisseurs prennent des raccourcis dans leurs SLA en se contentant de faire passer le trafic « réputé sûr », comme les CDN et les services de partage de fichiers, sans aucune analyse en raison de limites d’architecture, d’évolutivité ou de résilience. Cette conception est de plus en plus désuète dans un paysage de menaces en constante évolution, car les menaces transmises par le biais de sources fiables et réputées ne cessent d’augmenter.
Matière à réflexion :
Êtes-vous prêt à considérer tout le trafic provenant des CDN, des fournisseurs de clouds publics ou des services de partage de fichiers comme fiable ?
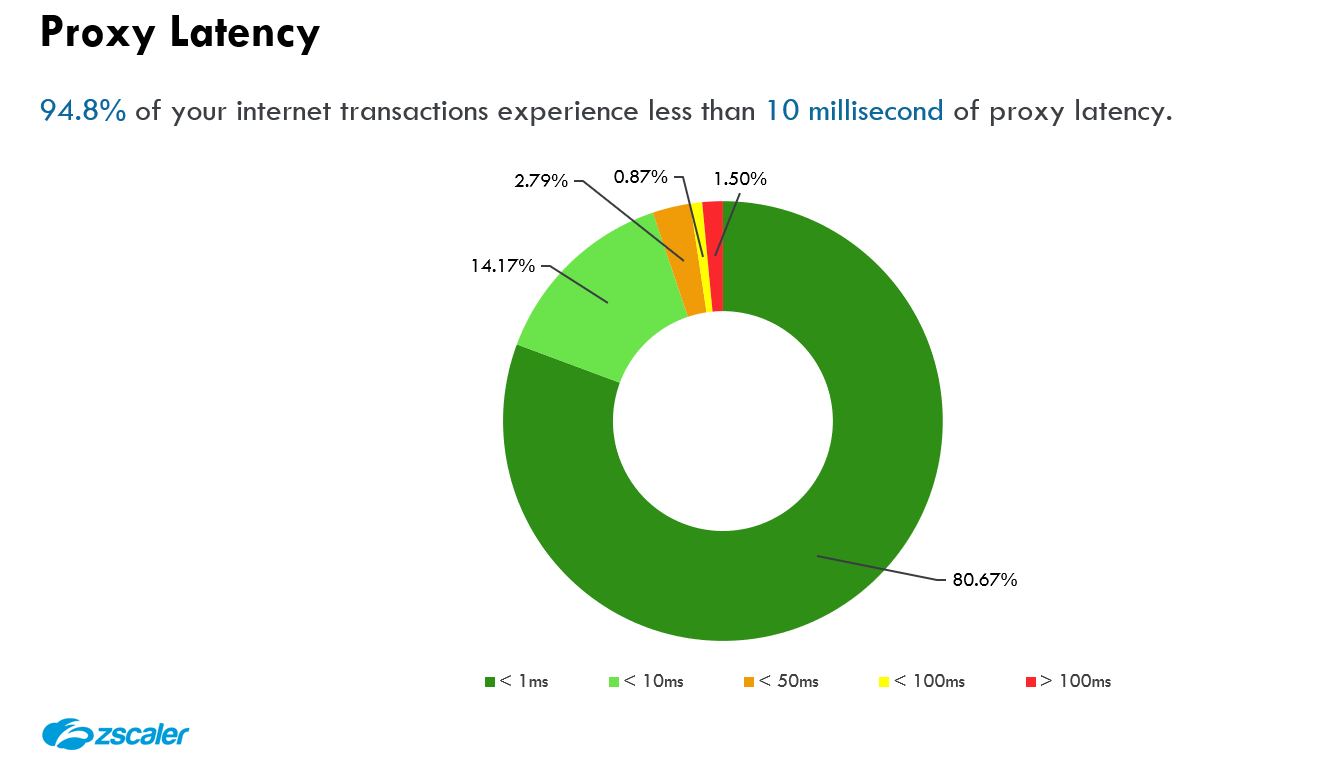
3. Le SLA de faible latence du proxy (vitesse fulgurante) —
L’inspection du trafic chiffré (sans limites) et l’application simultanée de moteurs de prévention des menaces et de la perte de données consomment des cycles CPU — cela relève de la physique. C’est ici que nous nous engageons à assurer une sécurité et une protection des données extrêmement efficaces et efficientes avec une expérience utilisateur exceptionnelle.
Examen approfondi du SLA sur la latence du proxy
Lorsque vous optimisez l’expérience utilisateur, vous devez tenir compte à la fois de la latence du réseau et de la latence du proxy. L’optimisation de la latence du réseau fera l'objet d’un autre blog, mais en bref, la latence du réseau est le temps écoulé entre le client et Zscaler plus le temps écoulé entre Zscaler et le serveur. La latence du réseau et la latence du proxy sont toutes deux fortement optimisées grâce à notre présence étendue au service edge et à notre capacité d’échange de peering. Quoiqu’il en soit, cette section se concentre sur la latence du proxy :

La latence du proxy est une mesure de couche 7 qui reflète le temps supplémentaire (en millisecondes) introduit par le proxy pour analyser la requête HTTP/S, plus le temps supplémentaire pour analyser la réponse HTTP/S. Dans le diagramme ci-dessus, la latence du proxy est X ms (requête) + Y ms (réponse). En tant que proxy de couche 7, Zscaler exécute de nombreux moteurs de sécurité et de protection des données à la fois sur les en-têtes/payloads de la requête et sur les en-têtes/payloads de la réponse, il est donc important de saisir les deux côtés.
Cette latence du proxy peut-elle être éliminée ? Non. Pour des raisons de physique : l’analyse de chaque transaction nécessite des cycles de CPU. Cette latence du proxy peut-elle être optimisée ? Oui, et nous y reviendrons brièvement plus loin dans ce blog.
La bonne manière de proposer des SLA de latence du proxy de pointe
Malheureusement, certains fournisseurs sont connus pour leur créativité en matière de clauses d’exclusion de SLA qui vont à l’encontre de la finalité même du SLA. Assurez-vous de comprendre ce qu’un fournisseur exclut exactement, la manière dont il calcule sa latence, et que cela ne semble pas trop beau pour être vrai.
1. Inclure l’analyse des menaces et la DLP
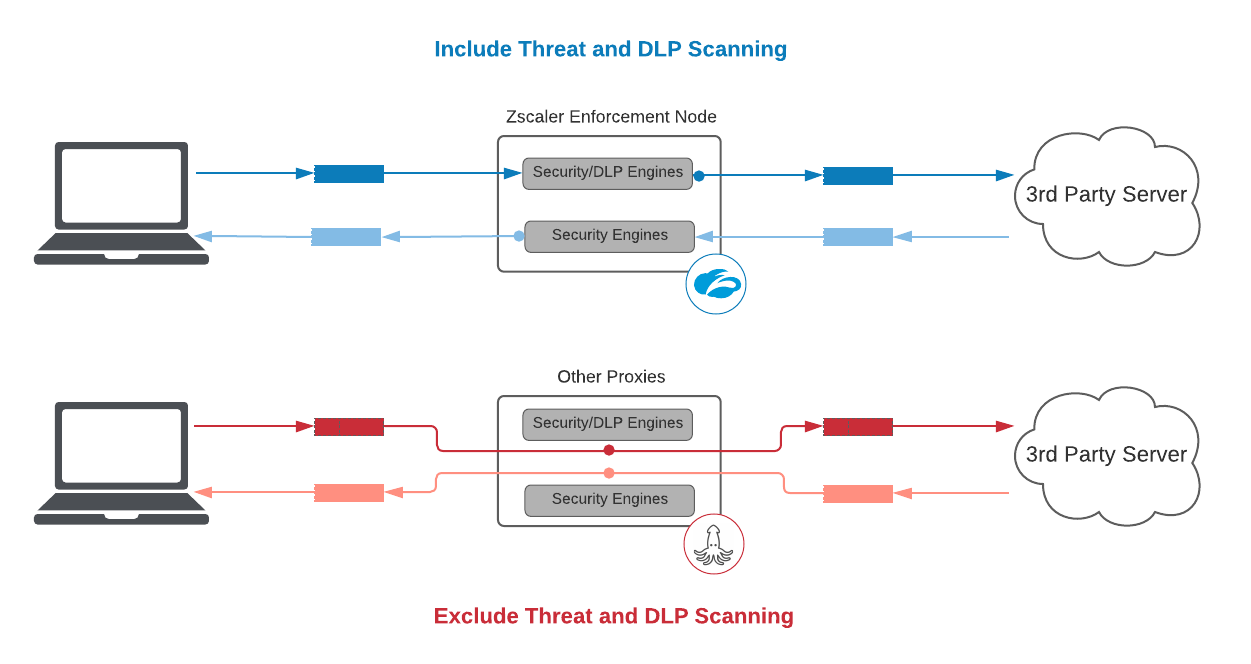
En tant que service de sécurité, l’exclusion de l’analyse des menaces et du DLP va à l’encontre de la finalité du SLA
Faire passer des paquets d’un côté à l’autre sans effectuer le moindre travail est « facile ». Soyez circonspect lorsque les fournisseurs proposent des chiffres de latence qui semblent trop beaux pour être vrais. En réalité, si Zscaler avait voulu offrir un SLA sans analyse des menaces ou DLP, nous pourrions proposer un accord de 25 ms et 5 ms pour le 95e percentile pour les transactions HTTPS déchiffrées et pour les transactions HTTP en texte brut, respectivement, soit 2 fois mieux que les autres fournisseurs, mais nous estimons que cette mesure n’est pas pertinente et qu’elle est très trompeuse envers nos clients.
Par exemple, un fournisseur de produits CASB ponctuels, non conçus pour le traitement du trafic inline, montre ses vraies limites dans les petits caractères :

Un SLA sur la latence du proxy ne doit pas exclure le temps supplémentaire introduit par ses moteurs.
2. Apporter de la transparence
C’est très simple : faites confiance, mais vérifiez toutes les déclarations de latence de votre fournisseur de sécurité cloud.
Un SLA sur la latence du proxy doit être assorti de rapports et de mesures au niveau des transactions émanant du fournisseur afin que ce dernier puisse être tenu responsable. Pas de données = pas de SLA.
Les détails au niveau des transactions sont la preuve réelle de l’impact de la latence et sont essentiels pour la transparence et le dépannage. La combinaison de mauvais choix d’architecture et de SLA agressifs place les autres fournisseurs dans une situation difficile pour satisfaire cette exigence :
- Les fournisseurs de produits CASB ponctuels contraints de se développer sur de nouveaux marchés : en s’appuyant sur un projet de proxy open-source non évolutif, il n’existe pas de plan de journalisation de niveau entreprise capable de saisir les journaux de niveau transactionnel (que les personnes du SOC qui lisent ceci s’en imprègnent bien). Les SLA ne peuvent pas être rapportés au niveau de la transaction avec cette approche même s’ils le voulaient… point final !
- Les fournisseurs de matériel obsolète qui essaient de rester pertinents : le chaînage de services de diverses fonctions avec des pare-feu de VM sur IaaS entraîne des chiffres de latence fragmentés et l’incapacité de rendre compte de la latence du proxy de bout en bout en temps réel.
En raison de l’incapacité ou du manque de volonté de faire preuve de transparence, un fournisseur CASB connu a été obligé d’utiliser des tactiques sournoises pour masquer les problèmes de latence sous le couvert d’une moyenne horaire. Comme ils ne peuvent pas journaliser au niveau de la transaction, la moyenne serait artificiellement faussée vers le bas pendant les heures de haute variabilité.
Zscaler a été créé dans un souci de transparence. Nous sommes à la fois désireux et capables de fournir à nos clients la visibilité que nous leur devons :
Rapport de latence fourni par Zscaler dans le cadre du rapport trimestriel d’activité (Quarterly Business Review — QBR)

Web Insights Log Viewer de Zscaler avec une visibilité de la latence du proxy au niveau des transactions
3. Se concentrer sur la latence des transactions du proxy par rapport à la latence des paquets du pare-feu
La latence des paquets donne une image incomplète de la latence, surtout dans notre monde orienté web.
Puisque nous parlons de latence du proxy, je serai relativement bref, mais il est important de comprendre la différence fondamentale. La latence des paquets est une mesure du temps qu’il faut à une appliance de pare-feu physique ou virtuelle pour traiter les paquets de requêtes (temps entre l’entrée et la sortie), cependant, cette mesure est imparfaite. La mesure du temps de traitement de la requête ne représente qu’une fraction de la latence globale de la transaction et ne tient pas compte de l’aspect le plus critique de la latence, à savoir la réception des informations en retour. La plupart du trafic web est par nature constitué de GET, avec de petits payloads mais de volumineuses réponses ; il s’agit là d’un sérieux malentendu sur la façon dont la latence devrait être mesurée dans notre monde centré sur le web.
L’ingrédient secret de Zscaler pour la meilleure latence de proxy de sa catégorie
La mise à l’échelle de l’infrastructure du cloud est la première étape, mais la solution optimale repose sur l’architecture sous-jacente adéquate. Zscaler analyse chaque paquet et le fait de manière extrêmement efficace grâce à des services de sécurité parallèles appelés Single Scan, MultiAction (SSMA) :
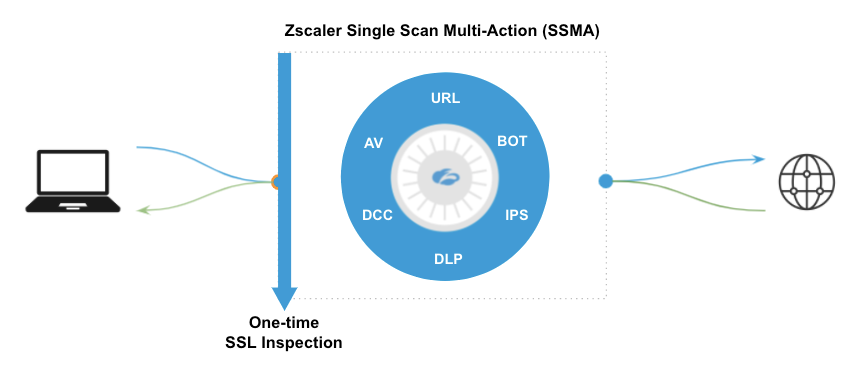
Moteurs Single Scan Multi-Action de Zscaler travaillant en parallèle
SSMA représente le meilleur de ce que les spécialistes de la sécurité demandent à l’industrie depuis des décennies : une plateforme unique qui concilie une sécurité de premier ordre et une expérience utilisateur rapide. C’est ce que Gartner appelle « l’inspection en un seul passage du trafic et du contenu chiffrés à la vitesse de la ligne » dans le cadre de SASE.
Avec les architectures traditionnelles, qu’il s’agisse d’appliances de chaînage de services, de services basés sur le cloud ou d’un mélange des deux, les paquets doivent quitter la mémoire d’une machine virtuelle (VM) vers une autre VM dans un différent data center ou un cloud complètement différent. Vous ne devez pas être un expert en physique ou en réseau pour comprendre à quel point cela est inefficace et extrêmement complexe.
Zscaler a été construit avec une architecture cloud native qui place les paquets dans la mémoire partagée de serveurs hautement optimisés, conçus pour un chemin de données optimisé. Plus important encore, tous les processeurs d’un nœud Zscaler peuvent accéder en même temps à ces paquets. En disposant de CPU dédiés pour chaque fonction, tous les moteurs peuvent inspecter les mêmes paquets en même temps (d’où le nom, Single Scan, MultiAction). Cela garantit l’absence de latence supplémentaire résultant du chaînage des services, ce qui permet au nœud Zscaler de prendre des décisions stratégiques extrêmement rapidement et de renvoyer les paquets vers Internet.
En résumé, la réaffectation d’appliances virtuelles obsolètes et de projets de proxy open-source en marque blanche avec des moteurs rajoutés ne fonctionne pas. La dette technique héritée est beaucoup trop importante pour pouvoir être traitée et compensée dans le cadre de ces approches.
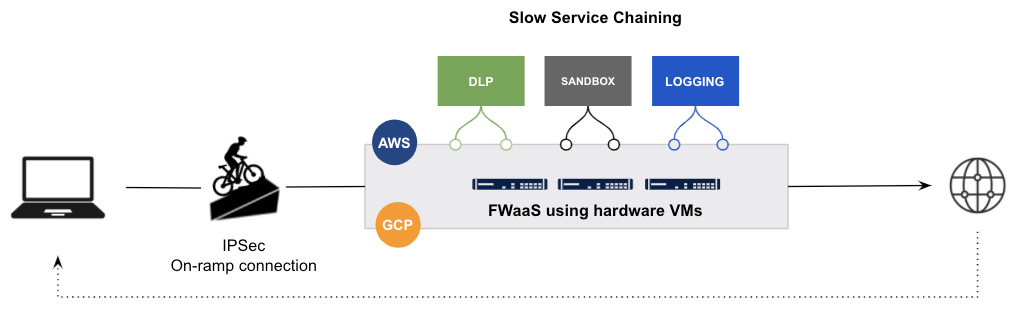
Exemple d’un fournisseur traditionnel qui réaffecte ses pare-feu de VM traditionnels sur IaaS avec un chaînage de services
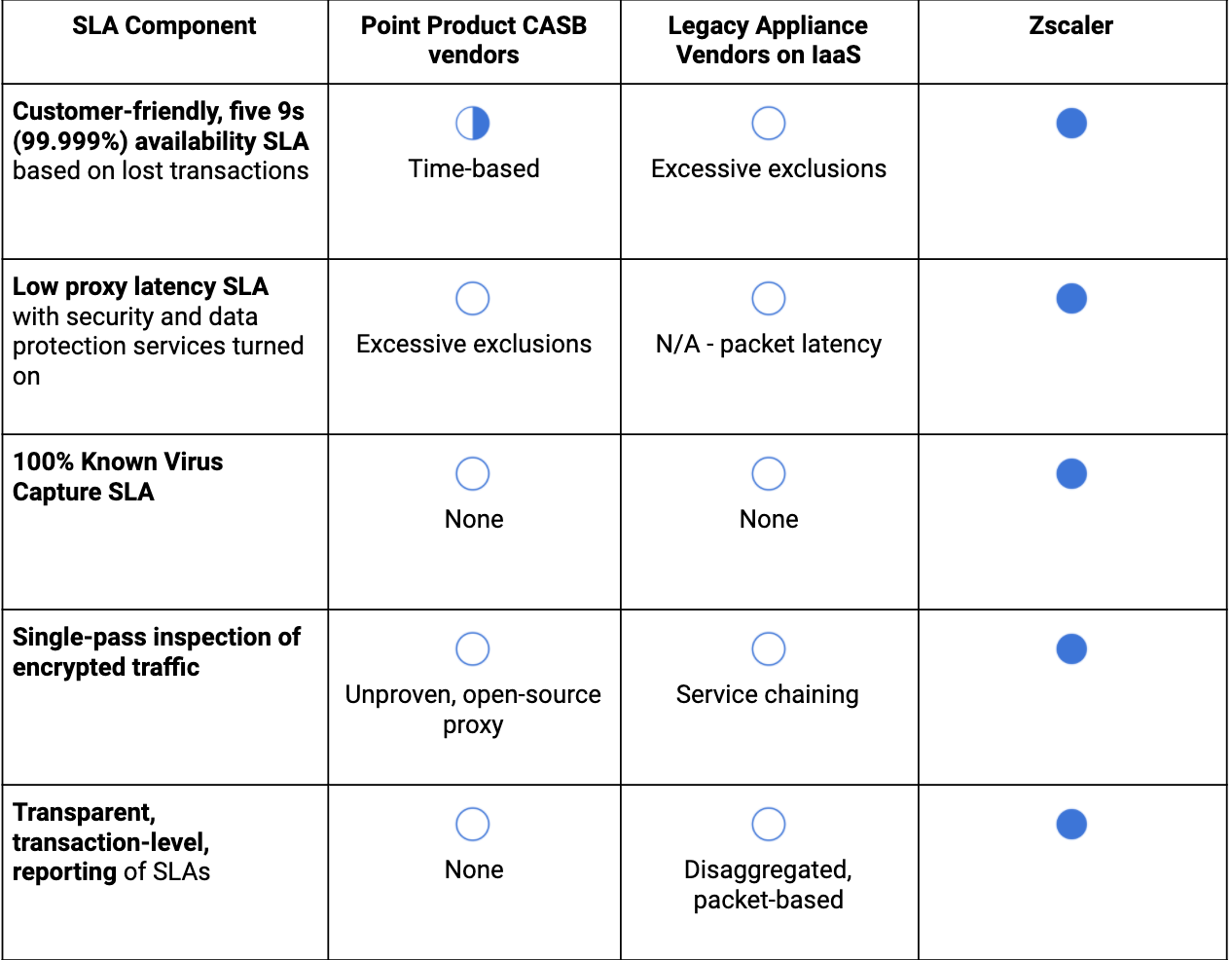
Assurez-vous de l’honnêteté de vos fournisseurs quant à leurs SLA
Voici un petit conseil sur la façon de mettre ces informations en pratique. Bon nombre de nos clients et prospects axent leurs discussions relatives aux SLA avec les fournisseurs sur la disponibilité, ce qui est certes une question très importante à soulever, mais qui laisse des lacunes dans l’analyse du service proposé par le fournisseur.
Vous trouverez ci-dessous un petit tableau qui vous permettra d’identifier les principaux composants des SLA qui vous seront proposés :